
Resolución de problemas estadísticos: cómo trabajar con datos complejos
P.: Tengo un conjunto de datos complejos que quiero usar para ayudar a resolver un problema. Me resulta difícil encontrar algo de valor potencial. ¿Puede ayudarme?
R.: Los datos complejos van más allá de lo que denominamos datos desordenados que, por lo general, consisten en datos inconsistentes, incompletos o categorizados incorrectamente. Con frecuencia, un conjunto de datos complejos no se crea considerando el problema. No obstante, está disponible de inmediato. Los datos complejos pueden provenir de enormes conjuntos de datos históricos o de conjuntos más pequeños provenientes de experimentación (sin diseño). Es posible que sean volátiles (extremadamente variables o inestables). No están planificados, suelen incluir muchas variables y, con frecuencia, demandan una estrategia multidimensional. Por estos motivos, se presentará un marco de trabajo junto con técnicas adecuadas para el manejo de datos complejos.
Aunque el objetivo es la extracción de significado, el primer paso es identificar el problema. Tomemos un ejemplo de bajo rendimiento con un defecto específico que interesa mejorar sin tener un impacto negativo en otros aspectos. Esta es una solicitud frecuente para extraer significado a partir de datos históricos. Si vamos más allá con este problema, se puede preguntar:
- ¿Siempre fueron bajos los rendimientos?
- Si no es así, ¿hay un momento aproximado cuándo empezó el problema?
- ¿Es algo intermitente? ¿Va y viene?
El esclarecimiento de estas preguntas sirve para definir mejor el problema y, además, permitirá que busquemos en el conjunto de datos correcto para dicho problema e identifiquemos las deficiencias del conjunto de datos disponible.
LEER MÁS: El significado de la confianza estadística
Luego, la comprensión y depuración de los datos es fundamental. Generalmente, esto comprende la rectificación de problemas de datos desordenados, tales como los datos inconsistentes, incompletos o categorizados incorrectamente. Para conocer más en detalle sobre estos pasos, puede consultar la metodología de procesos intersectoriales para la minería de datos (CRISP-DM, por sus siglas en inglés).¹
Una vez comprendido el problema y después de haber depurado nuestro conjunto de datos, es posible utilizar unas cuantas técnicas simples para obtener conclusiones ocultas en los datos.
1. Ver distribuciones con histogramas
Si los datos son continuos y si aplica los conocimientos que tiene en la materia, ¿espera datos distribuidos normalmente (Figura 1) o sesgados hacia la derecha (Figura 2)? O bien, ¿está encontrando datos bimodales, indicados por dos picos adyacentes, que debe entender mejor? La visualización de histogramas también puede ayudar a localizar datos erróneos que estuvieron anteriormente ocultos.
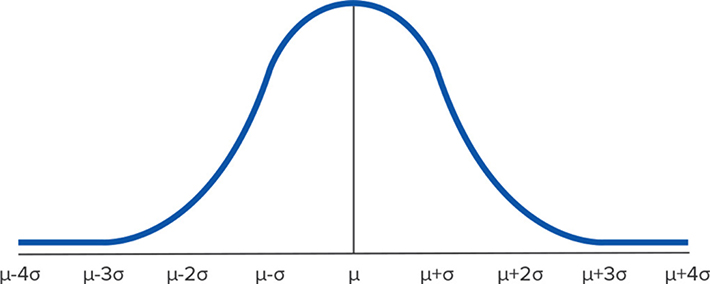
Figura 1 Histograma con distribución normal (E2586) que muestra la clásica campana de Gauss.
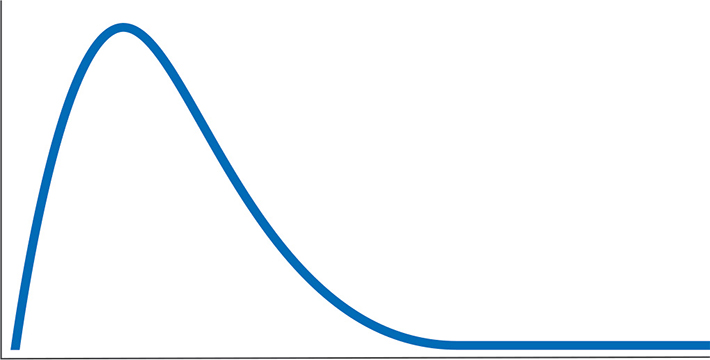
Figura 2 Un histograma sesgado hacia la derecha (E2586) es frecuente para variables que tienen una tendencia marcada al cero y tienen el límite inferior cero (en términos físicos, no puede tener un valor inferior a cero). Habitualmente, quienes no son especialistas confunden los valores más elevados de los datos sesgados hacia la derecha como valores atípicos y eliminan datos valiosos.
Es posible que otros datos sean discretos, los cuales tendrán la siguiente forma:
- Nominal: sin orden, tal como {masculino, femenino} o {proveedor n.° 1, proveedor n.° 2, proveedor n.° 3}
- Ordinal: se puede ordenar, por ejemplo, {grado de escuela secundaria, bachiller, maestría, doctorado}
Para cada categoría de una característica de datos discretos, ¿todos los niveles tienen una cantidad razonable de datos? ¿O faltan ciertos niveles?
El poder de esta técnica aparentemente simple es que es fácil de realizar y los gráficos brindan una variedad de conclusiones.
2. Explorar la influencia del tiempo
Quizá, ya sepa de la influencia del tiempo cuando formula preguntas para esclarecer situaciones (por ej., ¿cuándo comenzó este problema?). Posiblemente, haya descubierto un histograma bimodal en una variable de respuesta que se explica mejor con el tiempo. Tal vez conoce de un evento especial que pueda haber influido en los datos, como la pandemia de COVID-19. Puede ser útil la creación de un gráfico o un diagrama de control que trace los datos en orden temporal. Para que esta opción esté disponible, las fechas y las horas no deben eliminarse en el paso de depuración.
Esta técnica es muy potente, porque la capacidad de comprender los cambios conocidos o potencialmente sin descubrir en el tiempo permite descifrar los datos de forma correcta. A veces, es posible que no sea productivo tratar todos los datos disponibles del conjunto como si fueran un grupo homogéneo. Los datos más antiguos o cierto subconjunto de datos pueden no ser pertinentes para el problema actual.
3. Descifrar relaciones entre variables
Esto puede significar variables predictivas (x) ya que pertenecen a variables de respuesta (y) o cómo las variables de respuesta se relacionan entre sí. Esto se puede realizar trazando datos. Si es posible, use matrices de diagramas de dispersión como una forma eficaz de mostrar varios gráficos a la vez.
Ilustremos esto con un ejemplo de datos de fabricación donde una de las variables predictivas son el proveedor y las respuestas son dos tipos distintos de pruebas mecánicas. Este concepto va un paso más allá al codificar por color lo mejor de lo mejor (BOB) de las partes y lo peor de lo peor (WOW) de las partes cuando se revisan los diagramas de respuesta (Figura 3). Entonces, esos BOB y WOW se difunden en los diagramas restantes que también contienen variables predictivas. En este ejemplo, el diagrama con Proveedor (Figura 4), indica que el material del Proveedor 3 se correlaciona con los resultados más bajos de las pruebas mecánicas.
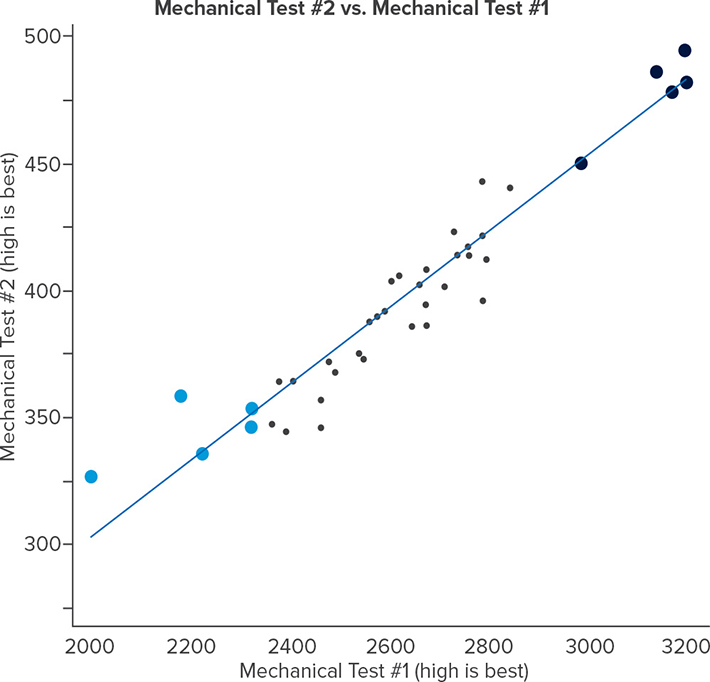
Figura 3 El propósito de este diagrama de ejemplo es principalmente entender la correlación de las respuestas. Además, lo mejor de lo mejor (BOB) y lo peor de lo peor (WOW) de las partes están codificados por color.
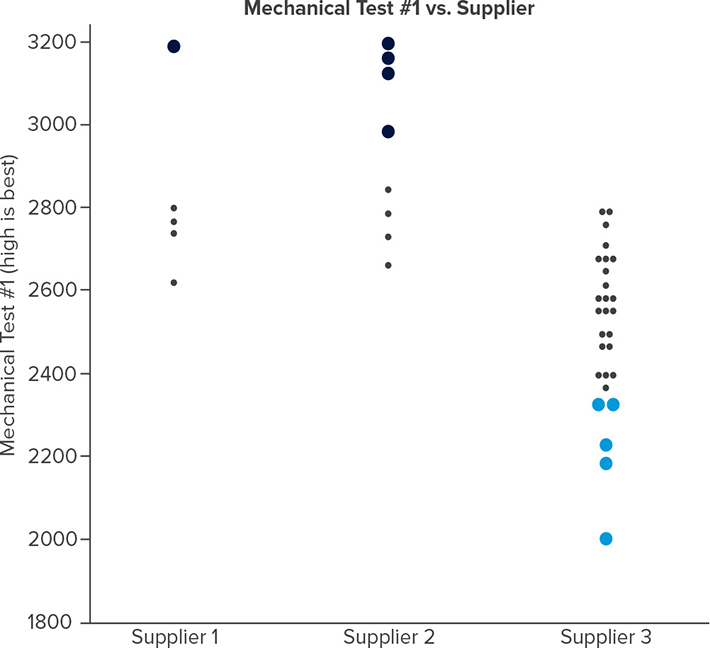
Figura 4 Lo mejor de lo mejor (BOB) y lo peor de lo peor (WOW) de las partes se difunden en diagramas que contienen variables predictivas.
¿Qué sigue después de aplicar estas técnicas? Dos opciones comunes para utilizar la información son:
- Optar por realizar análisis, que pueden guiarlo a usar una reducción en el período o una reducción en las variables.
- Llevar a cabo experimentaciones o validaciones adicionales en la región (espacio de diseño) de interés.
Los datos complejos pueden presentar una variedad de desafíos para los análisis significativos. Antes de indagar directamente en el análisis, es necesario que primero obtenga información. Esto es fundamental para determinar cuál es el mejor proceso a seguir. Ahora, juegue con sus datos y vea qué le pueden informar.
Referencias
¹ Hotz, N. “What is CRISP DM?” (¿Qué es CRISP-DM [Proceso Estándar en la Industria para Extracción de Datos]?) Data Science Process Alliance. 26 de marzo, 2024.
Carol Parendo es técnica sénior de Calidad empresarial en Collins Aerospace. Tiene más de 30 años de experiencia como ingeniera mecánica y estadística en los campos aeroespacial y de dispositivos médicos. Carol es miembro general del Comité sobre calidad y estadísticas (E11).
El Dr. John Carson es estadístico sénior de Neptune and Co. y coordinador de la columna Data Points. Es miembro de los comités de Calidad y estadísticas (E11), Productos derivados del petróleo, combustibles líquidos y lubricantes (D02), Calidad del aire (D22) y otros.
 Página Principal
Página Principal Archivo
Archivo La Mancheta
La Mancheta Enviar correo electrónico al editor
Enviar correo electrónico al editor Calendario Editorial (Inglés)
Calendario Editorial (Inglés)